Your application
Sees everything
It is the source of the prompt and the consumer of the rehydrated response. Privian does not change that.
Data path
See how prompts move through Privian, what gets masked, what never reaches the LLM, and where Privian fits in your AI stack.
Definition
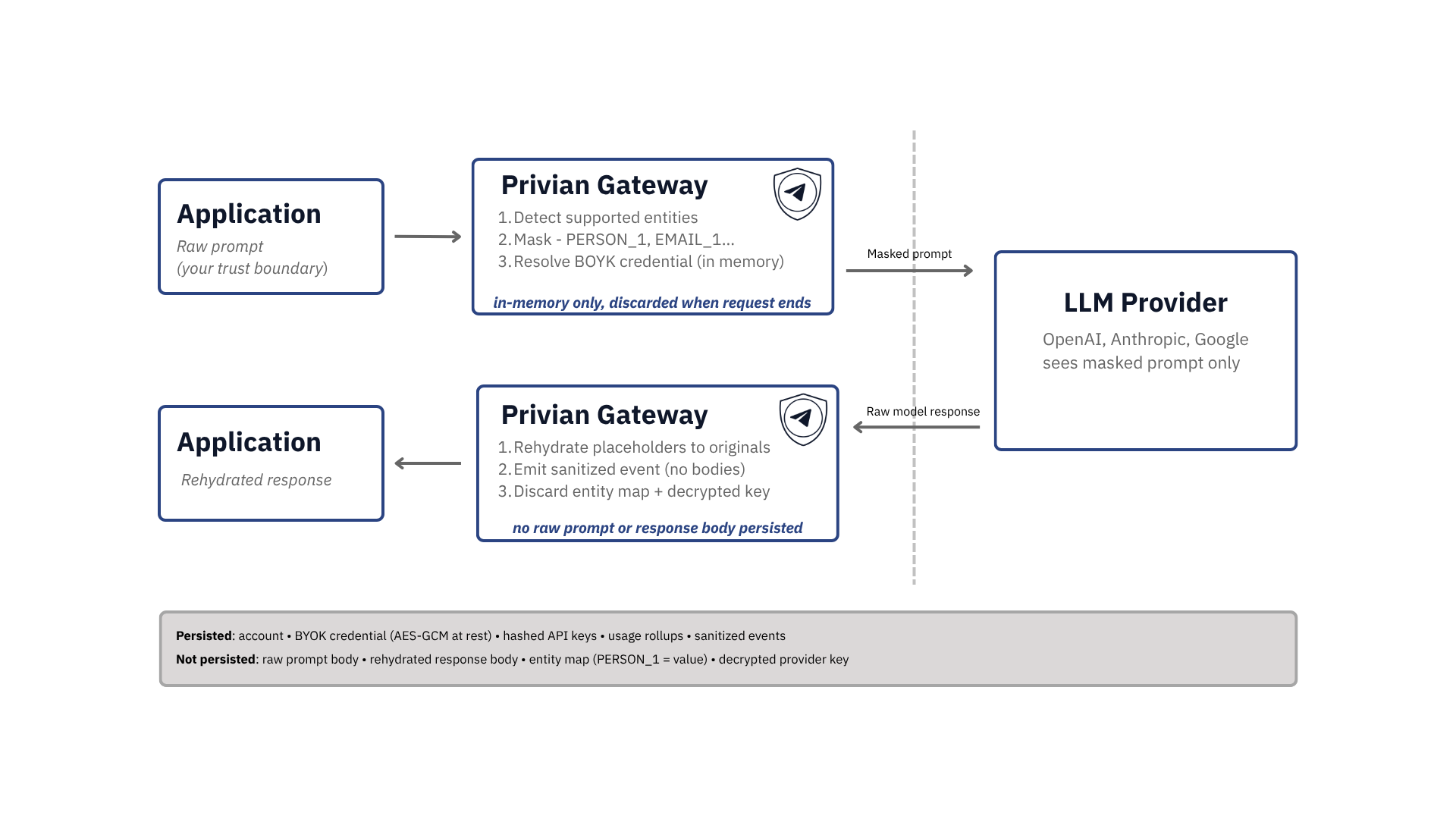
An AI data path describes what enters the model, what is retained, who can see it, and what is deleted. Privian's data path is a single in-memory pass: detect, mask, BYOK call, rehydrate, discard.
In one screen
Eight questions a security engineer, CTO or CISO usually asks first. Answers grounded in implementation, not marketing.
The model receives only the masked form of supported detected values; unsupported content passes through unchanged.
| Question | Answer |
|---|---|
| What reaches the model? | Your prompt with supported personal and sensitive values replaced by deterministic placeholders (PERSON_1, EMAIL_1, …). The provider sees the masked prompt only. |
| What never reaches the model? | The original surface-form values for entities Privian successfully detected and masked. They are replaced before the outbound provider call. |
| What gets retained? | Nothing of the raw prompt or rehydrated response body. Only structural counters and sanitized observability events (request id, model, token counts, latency, error class). |
| What does Privian store? | Account data, BYOK provider credentials (AES-GCM encrypted at rest), API keys (hashed), usage rollups and sanitized event metadata. |
| Who can see your prompt content? | Your application sends it, the upstream model provider receives the masked version, and the entity mapping lives in process memory for the request only. Privian staff cannot browse raw prompts because raw prompts are not retained. |
| What does Privian log? | Structural counters and event metadata only — never raw prompt or response bodies. Observability events are sanitized before they leave the request. |
| What is deleted? | The in-memory entity map and any decrypted provider key are discarded when the request ends. There is no raw prompt or response body to delete because none was written. |
| What are the limitations? | Privian masks supported entity types only. Anything outside that set (custom internal identifiers, free-text descriptions of sensitive context, novel formats) reaches the provider unchanged. See the limitations section below. |
Data path
Single in-memory pass. Nothing of the raw prompt or rehydrated response is written to storage.
Framework
Detect
Identify supported sensitive values in memory.
Mask
Replace originals with request-scoped placeholders.
Route
Send only the masked prompt to the selected provider.
Rehydrate
Restore mapped values before returning the response.
Discard
Drop the mapping and decrypted provider credential.
Region & residency
Said plainly so there is no ambiguity in a procurement review.
In the prompt
Placeholders are deterministic within a request — the same value mentioned three times becomes the same token three times, so the model can still reason about co-reference. On the way back, tokens are replaced with the original values inside the gateway before the response returns to your application.
In the prompt
Privian does not overclaim here. If a value falls outside the supported entity set, it is not masked and will reach the provider unchanged. The supported set is listed on PII masking.
At rest
Trust boundary
A calm honest read of which actors see what. No unsupported guarantees.
Your application
It is the source of the prompt and the consumer of the rehydrated response. Privian does not change that.
Privian (data plane)
Detection, masking, the BYOK provider call and rehydration happen in a single in-memory pass. Bodies are not written to storage.
Upstream provider
OpenAI, Anthropic, Google etc. receive your prompt with supported entities replaced by tokens. Their terms apply from there.
Privian staff
Raw prompt and response bodies are not retained, so there is no operator console for them. Support work uses request ids and sanitized events.
In your stack
One privacy layer inside a broader AI control stack — not a replacement for governance, self-hosted inference or prompt-injection defense.
Your application → Privian → Managed model provider Privian is: Privian is not: prompt-level data protection governance / policy engine privacy-first routing self-hosted inference BYOK + no raw-prompt retention prompt-injection / jailbreak defense small JSON contract audit-log product
Fit
Honest fit
Cases where another approach is the right tool. Said plainly.
Tradeoffs
Two different shapes of risk reduction. Neither is universally right.
Self-hosted models
Best when policy or regulation requires that data never leaves a controlled environment. You take on inference operations, capacity planning and model maintenance.
Managed models + Privian
Use GPT, Claude or Gemini, but mask supported sensitive values before the prompt reaches them, keep BYOK, and avoid raw-prompt retention at the gateway.
Hybrid
Highly sensitive workflows go to self-hosted inference; lower-risk workflows use managed providers through Privian. Common pattern for teams that want both.
Full side-by-side: Privian vs self-hosted LLMs.
Limitations
Read this list as the trust boundary. If your requirement is on this list, Privian is not the right tool — at least not on its own.
FAQ
Blueprint
Trust
The same picture from different angles — procurement-friendly references.
Trust & Security Review Center
Procurement-ready hub: data path, retention, BYOK and scope.
GDPR and LLMs
How prompt-level controls fit EU privacy expectations.
Security
Privian's security model, retention and credential handling.
Sub-processors
Providers Privian uses and what each one sees.
Privacy
Privacy notice for the Privian application and gateway.
Plans & pricing
Pricing for the Privian gateway is published transparently. Beta plans may change.
Keep reading
Operational security posture and trust boundaries.
How the gateway is built end-to-end.
Reducing prompt-level sensitive-data exposure under GDPR.
Supported entity types and how masking works.
The category for prompt-level data protection.
Prompt-level data protection in practice.
The hosted gateway in front of managed providers.
What no raw-prompt retention means in practice.
Privian vs other AI gateways and self-hosted models.
Provider relationships and the BYOK boundary.
Procurement and security-review resource center.
Evaluation package for security and procurement reviewers.
Framework for evaluating AI vendors end-to-end.
Per-hop review framework used in vendor approvals.